RSS-канал «Все статьи подряд / SQL / Хабр»

SQL - формальный непроцедурный язык программирования
Обработано роботом:
2024-05-05 06:27:51
Пополнены новости:
2024-05-03 11:00:07
Доступ к архиву новостей RSS-канала возможен только после подписки.
Как подписчик, вы получите в своё распоряжение бесплатный веб-агрегатор новостей доступный с любого компьютера в котором сможете просматривать и группировать каналы на свой вкус. А, так же, указывать какие из каналов вы захотите читать на вебе, а какие получать по электронной почте.
Подписаться на другой RSS-канал, зная только его адрес или адрес сайта.
Код формы подписки на этот канал для вашего сайта:
Последние новости
Цикл статей о Greenplum. Часть 1. GP под капотом
2024-05-03 10:38 imzorin (Axenix (ex-Accenture))

Всем привет!
Как вы знаете, многие поставщики ПО ушли с российского рынка ввиду введённых санкций и многие компании столкнулись с необходимость заняться импортозамещением в кратчайшие сроки. Не стал исключением и наш заказчик. Целевой системой, на которое было принято решение мигрировать старое хранилище, стал Greenplum (далее GP) от компании Arenadata.
Этой статьей мы запускаем цикл материалов посвященных Greenplum. В рамках цикла мы разберем, как вообще устроен GP и как выглядит его архитектура. Постараемся выделить must have практики при работе с данным продуктом, а также обсудим, как можно спроектировать хранилище на GP, осуществлять мониторинг эффективности работы и многое другое. Данный цикл статей будет полезен как разработчикам БД, так и аналитикам.
Читать далее
Большая иерархия в SQL запросе + PostgreSQL
2024-05-01 00:56 iqu

Сначала запрос адаптирован для работы в PostgreSQL 15.6.
Затем работа запроса проверена на достаточно объемной иерархии - в качестве источника данных использована структура архива jdk-master.zip из OpenJDK 22
Читать далее
Отображение части иерархии в SQL запросе
2024-04-26 23:29 iqu
Продолжение статьи, в которой предложено решение задачи визуализации иерархической структуры средствами SQL запросов, на примере MySQL и SQLite
В этой части производится доработка запросов для отображения части иерархии, начиная с конкретных узлов, и анализируются возможные связанные ошибки
Читать далее
[Перевод] Потенциальные проблемы с автоинкрементным ключом. MySQL <8.0, PostgreSQL
2024-04-15 12:42 alexmusyka

В данной публикации я поделюсь двумя основными причинами, по которым я предпочитаю избегать использования автоинкрементных полей в PostgreSQL и MySQL в будущих проектах. Вместо этого я предпочитаю использовать UUID-поля, за исключением случаев, когда есть очень веские аргументы против этого подхода.
Читать далее
Spark. План запросов на примерах
2024-04-15 09:12 val6789

Всем привет!
В этой статье возьмем за основу пару таблиц и пройдемся по планам запросов по нарастающей: от обычного селекта до джойнов, оконок и репартиционирования. Посмотрим, чем отличаются виды планов друг от друга, что в них изменяется от запроса к запросу и разберем каждую строчку на примере партиционированной и непартиционированной таблицы.
Читать далее
Отладка в SQL Developer
2024-04-10 13:31 awswaltz (CUSTIS)

Привет! Меня зовут Алексей Маряхин, я разработчик на Oracle. В этой статье продолжим знакомиться с темой отладки PL/SQL-кода.
В предыдущей статье мы изучили возможности отладки в PL/SQL Developer. В этой предлагаю рассмотреть ещё один инструмент — SQL Developer (версия 21.2.0.187 Build 187.1842). Также обозначим плюсы и минусы этих инструментов в сравнении.
Как оказалось, информации на русском языке на эту тему не так много, а документация по SQL Developer не отвечает на многие вопросы. В статье постараюсь осветить основные моменты касательно использования SQL Developer для отладки. Если тема для вас актуальна, велком!
Читать далее →
PostgreSQL 17: Часть 4 или Коммитфест 2024-01
2024-03-29 23:31 pluzanov (Postgres Professional)

Весна уже в разгаре, а мы вспомним горячие новости самого зимнего, январского коммитфеста. И сразу начнем с козырей.
Предыдущие статьи о 17-й версии: 2023-07, 2023-09, 2023-11.
Читать дальше →
Медленное выполнение команды TRUNCATE: анализ проблемы блокировок спинлока в SQL Server
2024-03-27 19:58 Mihpetu (Автомакон)

Приветствую всех читателей Хабра! Меня зовут Михаил, я администратор DBA в компании «Автомакон». На данный момент работаю на проекте для «ВкусВилл».
Решил затронуть одну из насущных проблем, связанную с работой SQL Server, а именно со спинлоками в нем. Да, даже такой зрелый и стабильный продукт как Microsoft SQL Server иногда подкидывает неожиданные задачи. Этот кейс хорошо демонстрирует, насколько увлекательные и интересные задачи решают администраторы баз данных.
Читать далее
Развитие баз данных
2024-03-27 13:15 angeloffy

В 60-х годах прошлого века возникла потребность в надежной модели хранения и обработки данных, особенно важной для банков и финансовых организаций. В то время отсутствовали единые стандарты работы с данными и моделями, и вся работа сводилась к ручной упорядоченной организации информации. Банкам удавалось записывать информацию о транзакциях в виде файлов в заранее подготовленную структуру, причем у каждой организации было собственное представление о том, как это должно выглядеть и функционировать. Также отсутствовали понятия консистентности (согласованности данных) и целостности данных. В таких файлах часто встречались дубликаты клиентов и их транзакций, которые приходилось уточнять и приводить в порядок вручную.
Данная статья захватывает ключевые моменты в развитии систем управления базами данных, от первых иерархических моделей до современных реляционных, NoSQL и NewSQL систем.
Читать далее
Автоматизация или как я избегала общения с коллегами. Часть 1
2024-03-26 21:21 IT_starter

Хочу написать небольшую серию постов о том, как я автоматизировала или ставила на конвейер какие‑то процессы, с разной степенью успешности, из личного и рабочего опыта. По функционалу это Python, SQL с привлечением Airflow, гитлаба и других стандартных инструментов.
Не поймите меня не правильно, я люблю людей, и своих коллег тоже (да, они тоже люди). Но когда им резко что‑то надо именно сейчас (ad‑hoc), и таких нуждающихся 30 человек‑ то я люблю их чуть меньше.
«Давай игнорировать ошибки» — бодро предложила я, и моя коллега меня поддержала. «Будет весело» — говорили они.
Я работала в нескольких высоко‑технологичных компаниях и командах, и далеко не все из моих коллег имели такое стремление хотя бы попробовать что‑то из рутины перевести в автоматический или полуавтоматический режим.
Что же я там выдумала
Как развернуть mysql в phpmyadmin с помощью docker
2024-03-25 12:30 m4deme1ns4ne

Как развернуть базу данных mysql в phpmyadmin с помощью docker.
Так как я не нашёл на русском нормальный материал, то решил написать самостоятельно.
Читать далее
Как пишут SQL-запросы гуманитарии
2024-03-25 11:21 osp2003

Когда говорят «мы ускорили выполнение нашего запроса в N раз» это значит, что сначала сделали плохо а потом начали думать как улучшить.
Так я думал раньше.
Читать далее
Статический анализ структуры базы данных (часть 1)
2024-03-25 10:50 nvv

Статический анализ структуры базы данных — это процесс выявления ошибок, нерекомендуемых практик и потенциальных проблем в базе данных только на основе структуры, типов данных, свойствах объектов. Статиеский анализ структуры не задействует ни пользовательские данные, ни статистику по таким данным.
Рассмотрим подробнее статический анализ структуры базы данных — что это, какие задачи решает, как интегрировать статический анализ в CI.
Читать далее
[Перевод] Разработка SQL Expert Bot: подробный гайд по использованию Vercel AI SDK и API OpenAI
2024-03-15 17:30 veseluha (BotHub)

OpenAI заложила фундамент для революции в сфере искусственного интеллекта с появлением ChatGPT, открывая новую эру в области AI, которую активно используют как отдельные люди, так и бизнес‑сообщества. OpenAI даже предоставила API для разработки персонализированных AI‑решений, включая чат‑ботов, виртуальных помощников и многого другого. Доступ к этому API можно получить через SDK, которые OpenAI выпустила для разных языков программирования, а также через оболочки, разработанные для удобства создания интерфейсов.
Компания Vercel внесла свой вклад, разработав AI SDK для создания интерактивных пользовательских интерфейсов с использованием TypeScript и JavaScript. Примечательно, что этот SDK является проектом с открытым исходным кодом и поддерживает Vercel Edge runtime.
В рамках данной статьи мы создадим SQL Expert ChatBot, применив API OpenAI и SDK от Vercel. Мы рассмотрим вопросы стриминговых ответов, настройки запросов и многое другое.
Читать далее
[Перевод] Охота на недостающий тип данных
2024-03-15 16:00 Bright_Translate (RUVDS.com)
Направленный граф — это набор узлов, связанных стрелками (рёбрами). Как узлы, так и рёбра могут содержать данные. Вот несколько примеров:
В сфере разработки ПО графы используются повсеместно:
- Зависимости пакетов, как и импорт модулей, формируют направленные графы.
- Интернет — это граф, состоящий из ссылок между веб-страницами.
- При проверке моделей анализ выполняется путём изучения «пространства состояний» всех возможных конфигураций. Узлы — это состояния, а рёбра — это допустимые переходы между ними.
- Реляционные базы данных — это графы, в которых узлы являются записями, а рёбра — внешними ключами.
- Графы — это обобщение связанных списков, двоичных деревьев и хэш-таблиц.1
Кроме того, графы также широко используются в бизнес-логике. Научные работы со ссылками формируют графы цитат. Транспортные сети представляют графы маршрутов. Социальные сети — это графы связей. Если вы работаете в сфере разработки, то рано или поздно встретитесь с графами.
Я вижу графы повсюду и использую их для анализа всевозможных систем. В то же время я побаиваюсь использовать их в коде. Какой из популярных языков программирования ни возьми, поддержка графов в них практически отсутствует. Ни в одном её нет в виде встроенного типа, очень мало где они прописаны в стандартной библиотеке, и у многих языков нет для этой функциональности надёжного стороннего пакета. Чаще всего мне приходится создавать графы с нуля. Существует большой разрыв между тем, как часто инженерам ПО могут понадобиться графы и тем, в какой степени экосистема их поддерживает. Где все графовые типы? Читать дальше →
5 стадий принятия необходимости изучения «плана запроса» или почему может долго выполняться запрос
2024-03-15 11:51 Iliukhin (БФТ-Холдинг)

Всем привет! Меня зовут Виктор, я работаю в Компании БФТ-Холдинг руководителем группы разработки. В этой статье разберем подходы и рекомендации по выявлению и устранению проблем с производительностью в системе базы данных Greenplum. Материал будет особенно полезен начинающим разработчикам Greenplum, которые пока не имеют достаточного опыта «чтения» плана запроса.
Если проблема затрагивает определенную рабочую нагрузку или запрос, можно сосредоточиться на настройке этой конкретной рабочей нагрузки. Если проблема с производительностью является общесистемной, то причиной могут быть аппаратные проблемы, сбои системы или конкуренция за ресурсы.
Читать далее
SQL HowTo: один индекс на два диапазона
2024-03-15 09:00 Kilor (Тензор)

В прошлой статье я показал, как условие с парой однотипных неравенств, плохо поддающееся индексации с помощью btree, можно переделать на эффективно gist-индексируемое в PostgreSQL условие относительно диапазонных типов, а наш сервис анализа планов запросов explain.tensor.ru подскажет, как именно это сделать.
Но что делать, если неравенств у нас не два, а целых четыре, да еще и с разными типами участвующих полей? Например, для целей бизнеса это может быть задачей вроде "найди мне все продажи за декабрь на сумму 10-20K", что на SQL будет выглядеть примерно так:
dt >= '2023-12-01'::date AND dt <= '2023-12-31'::date AND
sum >= 10000::numeric AND sum <= 20000::numeric
Использование Redis почти как SQL БД: Реализация чата с кешированием сообщений
2024-03-15 00:34 EugeneUshakov
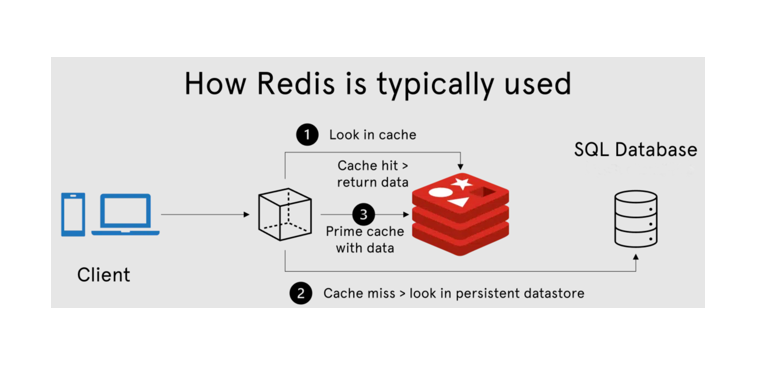
Допустим, мы хотим создать чат и хранить сообщения для него. Вполне возможно, мы можем добавить для этого простую базу данных (БД), такую как MySQL или даже NoSQL БД.
Обычно многие используют Redis как key‑value (dictionary) хранилище. Тем не менее, Redis — это несколько большее, чем key‑value, как многие привыкли думать.
Читать далее
Бьемся с индексацией парных неравенств в PostgreSQL
2024-03-11 15:00 Kilor (Тензор)

Я уже не раз писал, что условия с несколькими неравенствами (<, <=, >=, >) обычно плохо подходят для индексирования "классическим" btree, вызывают "тормоза", и необходимо придумывать различные нетривиальные подходы в PostgreSQL, чтобы добиться хорошей производительности подобного запроса.
В этой статье мы не только рассмотрим способы решения подобных задач "в общем виде", но и покажем, как нам удалось автоматизировать их решение в рамках функционала рекомендаций индексов нашего сервиса анализа планов explain.tensor.ru и его новых возможностях.
Читать далее
[Перевод] SQL в качестве API
2024-03-10 11:01 Albert_Wesker (Timeweb Cloud)

SQL в API???
Верно, вы уже успели подумать: «это же безумие, предоставлять API, который принимает SQL». Да, это ужасная идея. Особенно, если API обращён к Интернету. Делать так небезопасно, вы напрашиваетесь на атаки в виде SQL-инъекций. Поддержка такого интерфейса превратится в кошмар, а сама реализация бэкенда будет замкнута на конкретную технологию (это будет какая-нибудь база данных ANSI SQL).
Но справедливо ли такое суждение? Время его пересмотреть! Читать дальше →
