RSS-канал «Text Mining Explained»
Доступ к архиву новостей RSS-канала возможен только после подписки.
Как подписчик, вы получите в своё распоряжение бесплатный веб-агрегатор новостей доступный с любого компьютера в котором сможете просматривать и группировать каналы на свой вкус. А, так же, указывать какие из каналов вы захотите читать на вебе, а какие получать по электронной почте.
Подписаться на другой RSS-канал, зная только его адрес или адрес сайта.
Код формы подписки на этот канал для вашего сайта:
Последние новости
How Long Is The Nile River?
2007-01-11 12:40 krondix
Понадобилось недавно узнать точную длину реки Нил, и, вместо Википедии, я решил спросить об этом у поисковиков. Сначала я задавал вопрос "how long is Nile?". Правильным ответом будем считать 6695 км или 4160 (4184) миль. Вот что получилось:
- Google: правильный ответ в втором и третьем сниппетах
- Yahoo: правильный ответ в четвертом сниппете
- Live: первый сниппет показывает нам длину реки Атбара, которая впадает в Нил, длина Нила лишь в восьмом сниппете
- MSN: как самый хитрый показал перед выдачей "Nile River length: 6695 km/4160 mi" с ссылкой на Encarta, при этом первый сниппет также содержит вносящую путаницу длину реки Атбара, но в третьем, шестом и седьмом — правильный ответ!
- Hakia: правильный ответ в пятом и седьмом сниппетах, при этом ни там ни там ответ не подсвечен, что ожидалось
Выводов никаких делать не буду, использовать MSN вместо Google тоже не начну, только лишь добавлю Hakia в список поисковиков в Firefox.
Hakia — поиск смысла
2007-01-03 14:31 krondix
Продолжая тему кластерного поиска. Новый поисковик Hakia (http://www.hakia.com) делает, пожалуй, самые интересные шаги в этом направлении. "The basic promise is to bring search results by meaning match - similar to the human brain's cognitive skills - rather than by the mere occurrence (or popularity) of search terms."
Я, конечно же, захотел проверить Hakia на своем любимом запросе "nokia 6230i". К моему удивлению, я увидел самую обыкновенную плоскую выдачу! Вернее, почти обыкновенную. В сниппетах выделены не просто ключевые слова запроса, а иногда и целые предложения или их части. Например, "The Nokia 6230i imaging phone combines advanced image and video features", "downloads and customer service information for your Nokia 6230i phone.", "to separate the Nokia 6230i from the 6230 apart from the vastly improved joystick" и др. Видно, что Hakia пытается понять о чем страница и показать самый релевантный смыслу страницы кусок в сниппете (не забывая, конечно, о поисковом запросе). Вполне возможно, это может сэкономить некоторое время — надо читать не весь сниппет, а заранее выделенный кусок — чтобы это проверить, надо попользоваться Hakia подольше.
Где же обещанный кластерный поиск? На наш запрос "nokia 6230i" маленькая зеленая голова под строкой поиска ответила (текст выбирается случайно): "Tough question! See if the results below help. ...See the hakia gallery for Nokia". Идем по ссылке (запрос "Nokia"), первая страница выдачи это, так называемая, галерея — набор кластеров с двумя ссылками в каждом. Headlines; Stock Quote and Company Website ; News, Company Profile; Company Heritage; Press Releases; Investors Page; Corporate Leadership; Employment and Career Opportunities; Brands; Industry and Peers; Criticism, Commentary, and Interpretations; Community Outreach and Philanthropy; Location and Contact Information — кластера хорошие, с правильными названиями и правильными ссылками в них. Смущают только две вещи. Во-первых, hakia gallery выдается не по всем запросам. Во-вторых, я не нашел способа посмотреть что еще есть в том или ином кластере. Имя кластера это не ссылка, а если набрать запрос "Nokia headlines", мы увидим совсем не те новости, которые нам предлагали в галерее.
Nutch и Hadoop, первые впечатления
2006-12-27 21:57 krondix
Nutch построен на основе Hadoop — это фреймворк, реализующий идею MapReduce. Расскажу кратко основную идею. Термины map и reduce пришли из функционального программирования, где они означают следующее: reduce это функция типа α -> β, map — функция типа (α -> β) -> [α] -> [β]. То есть map применяет переданную ей первым аргументом функцию reduce к списку элементов типа α и на выходе получается список элементов типа β. Например, если мы определим функцию square x = x ∗ x, вызов map square[1,2,3] вернет [1,4,9]. Если reduce функция без побочных эффектов (то есть она не изменяет ничего за пределами своей области видимости), то применять ее можно одновременно к нескольким элементам входного списка. Гугловый фреймворк MapReduce позволяет прозрачно для программы разносить эти вычисления по многим машинам. Hadoop представляет собой open-source реализацию этой же идеи на Java.
Итак, исходники скачаны, первое, что необходимо сделать — настроить запуск их среды разработки. Как это сделать для Eclipse описано здесь, перескажу вкратце с одним дополнительным шагом для IDEA.
- При создании нового проекта IDEA найдет все папки с исходниками (их там много).
- В dependencies надо добавить все *.jar из lib и src/plugin/*/lib. К hadoop-*.jar лучше подключить исходники или (лучше) настроить Hadoop соседним модулем в проекте.
- Пометить папку conf как source folder. В настройках компилятора в Resource Patterns добавить ?*.txt, если этого не сделать *.txt файлы из conf, не будут видны в рантайме и Nutch работать не будет.
- В nutch-site.xml (или nutch-defaults.xml) прописать свойство plugin.folders как src/plugin
- Прописать в defaults VM arguments: -Dhadoop.log.dir=logs -Dhadoop.log.file=hadoop.log
К сожалению, какая-либо внятная и полная документация по Nutch и Hadoop отсутствует, API также практически не задокументирован, а код не слишком читабелен. Без дебагера разобраться сложно. Плюс эти товарищи повсеместно используют конструкцию, за которую надо просто отрывать руки:
try {
url = urlNormalizers.normalize(url, URLNormalizers.SCOPE_INJECT);
url = filters.filter(url);
} catch (Exception e) {
if (LOG.isWarnEnabled()) { LOG.warn("Skipping " +url+":"+e);
url = null;
}
Если произойдет исключение, то мы увидим только его класс, а stacktrace нам не покажут. Нам даже не скажут на какой строчке какого класса оно произошло. Метод warn у логгера (и все остальные тоже) специально перегружены, чтобы корректно обрабатывать такую ситуацию, достаточно вместо плюса поставить запятую — LOG.warn("Skipping " +url+":", e) — и будет выведен нормальный stacktrace, из которого легко понять что происходит.
В целом же, Nutch работает: качает и ищет. В дальнейших планах написать пару плагинов к нему для особого парсинга скачанных страниц, развернуть его на кластере и разобраться с API Hadoop. Обо всем это, естественно, напишу.
Классификация документов
2006-12-18 00:15 krondix
С результатами автоматической классификации документов встречались, практически, все, кто пользовался электронной почтой. Спам-фильтры классифицируют входящую почту по двум категориям "спам"/"не спам" с помощью самых разных алгоритмов, начиная от простых decision trees задаваемых пользователем до сложных статистических методов. Далее мы рассмотрим несколько самых распространенных алгоритмов классификации и поймем как можно оценить и сравнить результаты работы этих алгоритмов.
Начнем с формулировки задачи. У нас есть некоторый набор категорий и документы, про которые известно, что они принадлежат одной из категорий. Пример: любой веб-каталог (Яндекс.Каталог, Yahoo Directory и другие), где сайты классифицированы по тематике. Эти документы составляют обучающую выборку для классификатора. Задача заключается в определении (точнее, предсказании с определенной вероятностью) категории для документов не входящих в обучающую выборку.
Очевидный способ классифицировать документ известный под названием алгоритм ближайшего соседа (nearest neighbour, NN) — найти в обучающей выборке наиболее схожий с ним и предположить, что их категории совпадают. В качестве меры похожести обычно используют расстояние или косинус угла между векторами. Самый простой в реализации, этот алгоритм оказывается и самым медленным, он линейно зависит от числа документов в обучающей выборке. На практике обычно используется модификация алгоритма ближайшего соседа — алгоритм k-ближайших соседей (k-nearest neighbours, k-NN). Здесь ищутся k наиболее близких документов из обучающей выборки и в качестве искомой категории выбирается встречающаяся чаще других в найденных документах. Так поступают, чтобы снизить влияние шума в обучающей выборке на результат. Шумом могут быть как просто неправильно классифицированные документы, так и документы, которые содержат много слов характерных для другой категории. Из-за невысоких показателей качества и, в первую очередь, низкой скорости алгоритм k-ближайших соседей редко применяется в промышленных разработках.
Следующий алгоритм, который мы рассмотрим, многие применяли и применяют в повседневной жизни. Создавая правило "always trust e-mails sent from address name@company.com" в почтовом клиенте, мы неявно управляем деревом принятия решений (decision tree), с помощью которого работают многие спам-фильтры. В нелистовых узлах дерева решений содержатся своего рода "вопросы" к документу, в листьях — ответы в виде результирующей категории. "Вопросы" могут задаваться самим пользователем, как в примере выше, так и вычисляться на основе обучающей выборки — в этом случае они обычно имеют вид "присутствуют ли в документе такие слова?" Простота идеи компенсируется сложностью построения такого дерева вопросов из набора документов, если интересно — напишу об этом отдельный пост. Кроме классификации, построенное дерево решений можно использовать для анализа структуры документов и категорий, что может может оказаться ценным само по себе. На практике, деревья решений используют в основном с этой целью, потому что по качеству классификации они сильно проигрывают классификаторам Байеса и линейным моделям, о которых пойдет речь дальше.
Про классификаторы Байеса я уже неоднократно писал, напомню основную идею. Для каждого слова мы считаем вероятность его принадлежности к каждой категории, вероятность принадлежности документа к категории считается как произведение вероятностей входящих в него слов. Несмотря на кажущуюся сложность такой формулы, по своей структуре это всего лишь линейная комбинация определенного числа параметров.
 Здесь
Здесь xi равно 1, если слово i присутствует в документе x, и 0 в противном случае. Таким образом задача классификации сводится к вычислению весов wi и смещения b для каждой категории и метод Байеса лишь один из многих способов их вычисления, причем не самый лучший. Заметим, что веса (wi,b) образуют гиперплоскость в пространстве слов, по одну сторону от которой лежат документы принадлежащие категории, по другую — не принадлежащие. Очевидно, что существует бесконечно много таких гиперплоскостей разделяющих документы из обучающей выборки. Идея, лежащая в основе метода опорных векторов (support vector machines, SVM), заключается в выборе разделяющей гиперплоскости, которая максимально удалена от всех документов. На данный момент, SVM считается самым точным алгоритмом классификации документов.Для оценки качества классификации обычно используют следующий метод. Набор документов с известными категориями делят на две части: на одной обучаются, на другой тестируют. При этом предполагается, что документы, которые придется в будущем классифицировать, будут похожи на документы из тестовой выборки. Это, конечно, может оказаться совсем не так, но, к сожалению, другого способа оценить качество классификации пока нет. Общепринятыми характеристиками качества классификации являются точность и полнота. Точность вычисляется как отношение числа правильных положительных предсказаний классификатора (когда документу была присвоена какая-либо категория) к числу общему числу положительных предсказаний. Полнота это отношение числа правильных положительных предсказаний к числу документов, которым должна была быть присвоена категория. У классификаторов с высокой точностью, обычно, низкая полнота и наоборот. Например, если спам-фильтр работает с высокой точностью и низкой полнотой, он будет очень редко класть в папку spam хорошее письмо, но при этом некоторая часть спама может остаться в inbox. Для каждого алгоритма классификации, как правило, есть возможность управлять соотношением точность-полнота.
Представление текстовых данных
2006-12-11 13:43 krondix
Перед применением какого-либо алгоритма text mining набор текстовых документов надо преобразовать в более удобный вид. Общепринятым представлением является векторная модель (vector space model). Пусть у нас есть
n документов, которые все вместе состоят из m уникальных слов. Каждому документу можно поставить в соответствие вектор d ∈ Rm, такой что di = 1, если слово i содержится в документе, и di = 0 в противном случае. Мы получили самую простую двоичную векторную модель. Как я уже говорил, важным свойством такого представления является разреженность, действительно, m может быть очень большим числом (несколько сотен тысяч), в то время как число единиц в каждом векторе может не превышать нескольких десятков. Это позволяет хранить в памяти не всю матрицу n ∗ m (1 000 000 ∗ 100 000 = 100 000 000 000 бит = 12.5 гигабайт), а лишь очень малую ее часть, обычно около 0.01-0.1%.Недостатки двоичной модели очевидны: мы никак не учитываем важность слов для документа. Согласитесь, слова "новый" и "телефон" вносят совершенно разный вклад в определении тематики документа (если мы рассматриваем описания различных товаров). Очевидное развитие двоичной модели для решения этой проблемы: учитывать не только наличие/отсутствие слова, но и его встречаемость в документе. Таким образом, вместо единицы, в качестве элемента вектора, будет число раз, которое данное слово встречается в документе.
К сожалению, попробовав такую модель, мы сразу увидим, что самыми частыми словами будут союзы и предлоги, которые, в то же время, не оказывают практически никакого влияния на тематику документа. Такие слова называются стоп-слова (stopwords) и их удаляют из документов перед преобразованием в векторную модель. Помимо общего словаря стоп-слов (куда входят союзы, предлоги, некоторые наречия, одиночные буквы и цифры и т.д.), для каждой конкретной задачи будет полезным составить свой собственный словарь (пример).
Еще одной техникой препроцессинга, помимо удаления стоп-слов, является стемминг (или лемматизация): выделение значимой части слова. С помощью стемминга слова "телефоны" и "телефона" приведутся к одному слову "телефон", что, помимо улучшения качества работы выбранного алгоритма, еще и значительно сократит словарь (а значит вырастет скорость работы). Хорощий обзор свободно доступных морфологических анализаторов можно найти в статье Губина и Морозова.
Описанная частотная модель, тем не менее, тоже не лишена недостатков. Некоторые слова могут встречаться в почти во всех документах и, соответственно, оказывать малое влияние на принадлежность документа к той или иной категории. Для понижения значимости таких слов используют модель TF∗IDF. TF (term frequency) это отношение числа раз, которое слово
t встретилось в документе d, к длину документа. Нормализация длиной документа нужна, чтобы уравнять в правах короткие и длинные (в которых абсолютная встречаемость слов может быть гораздо больше) документы. IDF (inverse document frequency) — это логарифм отношения числа всех документов к числу документов содержащих слово t. Таким образом, для слов, которые встречаются в большом числе документов IDF будет близок к нулу (если слово встречается во всех документах IDF равен нулю), что помогает выделить важные слова. Коэффициент TF∗IDF равен произведению TF и IDF. TF играет роль повышающего множителя, IDF — понижающего. Соответственно, вместо простой частоты встречаемости элементами векторов-документов будут значения TF∗IDF. Во многих задачах (но не во всех) это позволяет заметно улучшить качество.
Таким образом, для слов, которые встречаются в большом числе документов IDF будет близок к нулу (если слово встречается во всех документах IDF равен нулю), что помогает выделить важные слова. Коэффициент TF∗IDF равен произведению TF и IDF. TF играет роль повышающего множителя, IDF — понижающего. Соответственно, вместо простой частоты встречаемости элементами векторов-документов будут значения TF∗IDF. Во многих задачах (но не во всех) это позволяет заметно улучшить качество.
Google Translate, Russian
2006-12-06 17:40 krondix
Text mining, in contrast to his elder brother, data mining, a relatively young field of computer science, the most significant results were obtained in the past 10 to 15 years. It seems to me that this is linked primarily to the emergence of a very large number of available each text and the appearance of the volume computing power. For the data mining input are some facilities with a small number of properties, which made certain conclusions. For example, the object could be history, characteristics, the results of tests and examinations, and the findings accordingly diagnosis. The text mining operate with a set of documents, the words of which are the same as properties. The size of such documents can be very large (several thousand words), and the size of the dictionary for all documents can reach several hundreds of thousands of words. Here, it should be noted, an important feature set of documents : if present it in the form of a matrix dokumentslovo (where there isКритерием достижения стопроцентного результата в машинном переводе считается двойной перевод, например, русский-английский-русский:aij1,if the wordjcontained in documentiand0otherwise), we see that it is highly razrejennouu structure, the majority of well0. This enables us to develop effective (memory and speed) algorithms for processing very large volumes of data.
Текстовая добыча - в отличие от своего старшего брата, добыча данных, что является относительно молодым области применения компьютерной техники,наиболее важные результаты были получены в последние 10-15 лет.Мне кажется, что это прежде всего связано с появлением очень большого числа доступных каждому тексту, а также появлением большого объема вычислительной мощности.За добычу данных материалов некоторые объекты с небольшим числом свойств, что сделало определенные выводы.Например, объект может быть история, характеристики, результаты тестов и экзаменов, а выводы, соответственно, диагноза.Текст горного работать с пакетом документов, словами это те же свойства.Размеры таких документов может быть очень большим (несколько тысяч слов),и размер словарь для всех документов может достигать нескольких сотен тысяч слов.Здесь надо отметить, одной из важных особенностей комплекса документов :Если представить ее в виде матрицы, dokumentslovo (где естьКак видно, результат получился гораздо хуже оригинала. Тем не менее, основной смысл сохранен, если догадаться что такое "текстовая добыча" и "добыча данных" понятно, практически, все.aij1, если выражение й содержащихся в документе я не0),Вы видите, что это весьма razrejennouu структуре, а большинство из0.Это позволяет создавать эффективные (память и скорость) алгоритмы для обработки очень больших объемов информации.
Машинный перевод (machine translation) является частью более общей задачи обработки текстов на естественных языках (natural language processing, NLP) и, возможно, наиболее сложной. Среди прочих задач NLP можно выделить распознавание речи, ответы на вопросы, авто-реферирование, проверка правильности текстов. Существует два главных направления в NLP: семантическое (когда мы пытаемся понять семантику слов и предложений) и статистическое (обучение на каком-либо корпусе текстов, для получения различной статистики взаимодействия слов). Статистические методы в NLP пришли из text mining, семантические методы NLP в свою очередь применимы в области извлечения информации (information extraction).
Возращаясь к Google Translate, забавный факт: почему-то заголовок "Text Mining Explained" был переведен (с русского на английский) как "Text Mining Casino".
Text Mining Books
2006-12-03 13:35 krondix
- Text Mining: Predictive Methods for Analyzing Unstructured Information (Sholom M. Weiss, Nitin Indurkhya, Tong Zhang, Frederick Damerau). Эта книга — краткое, но в то же время достаточно полное введение в text mining. Подготовка данных, классификация, кластеризация, поиск, извлечение информации — всему нашлось место в книге, причем некоторые алгоритмы описаны очень подробно. Самой интересной мне показалась шестая глава, посвященная статистическим методам в извлечении информации (information extraction). Резюме: специалистам в text mining книга поможет структурировать имеющийся объем знаний, для новичков же она прекрасное введение в область.
- Survey of Text Mining: Clustering, Classification, and Retrieval (под редакцией Michael W. Berry). Здесь собраны лучшие работы участников Text Mining Workshop проведенного в рамках Second SIAM International Conference on Data Mining (SDM) в 2002-ом году. Наиболее интересные, на мой взгляд: мягкий (soft) алгоритм k-средних с автоматической расстановкой весов отдельным словам, алгоритмы кластеризации PDDP (Principal Direction Divisive Partitioning) и sPDDP( spherical PDDP), Latent Semantic Indexing и Covariance Matrix Analysis (известный также как Principal Component Analysis) и их модификации для лучшей обработки маленьких кластеров. Три перечисленных алгоритма кластеризации (кроме LSI) используют по сути один и тот же метод: нахождение одного или нескольких собственных векторов матрицы ковариантности. Чуть позже напишу об этом подробнее, это действительно очень интересно.
Что такое text mining
2006-12-03 13:34 krondix
Text mining, в отличие от своего старшего брата data mining, сравнительно молодая область computer science, большинство значительных результатов было получено в последние 10-15 лет. Как мне кажется, связано это в первую очередь с появлением очень большого количества доступной каждому текстовой информации и появлением соответствующих таким объемам вычислительных мощностей. Для задач data mining входной информацией являются некоторые объекты с небольшим числом свойств, на основании которых делаются определенные выводы. Например, объектом может быть история болезни, свойствами — результаты анализов и осмотров, а выводы, соответственно, диагноз. Системы text mining оперируют с набором документов, слова из которых можно аналогичным образом считать свойствами. При этом размер таких документов может быть очень большим (несколько тысяч слов), а размер общего словаря по всем документам может достигать нескольких сотен тысяч слов. Здесь нужно отметить одно важное свойство набора документов: если представить его в виде матрицы документ-слово (где элемент
aij равен 1, если слово j содержится в документе i и 0 в противном случае), мы увидим, что она имеет сильно разреженную структуру, то есть большинство элементов равно 0. Это позволяет создавать эффективные (по памяти и скорости) алгоритмы обработки очень больших объемов данных.Задачи text mining
- Классификация (classification). Задача заключается в отнесении документа к одной из нескольких заранее определенных категорий, основываясь на содержании документа. Для построения классификаторов используется обучающая выборка из документов с присвоенными им категориями. Классический пример: классификация писем по категориям спам/не спам. Самые простые классификаторы: метод k ближайших соседей и классификатор Байеса.
- Кластеризация (clustering) отличается от классификации тем, что мы не знаем какие существуют категории. У нас нет никакой обучающей выборки, есть только документы, которые надо попытаться определенным образом сгруппировать в кластеры (категории). Причем, как правило, неизвестно даже число возможных категорий (хотя его можно более-менее точно оценить. Существует два типа алгоритмов кластеризации: одни работают с заранее определенным числом категорий (например, алгоритм k-средних), другие с неизвестным (например, иерархическая кластеризация). Известные примеры использования кластеризации: Яндекс.Новости и Nigma.
- Извлечение фактов (fact/information extraction). Название говорит за себя, задача заключается в извлечении из неструктурированного текста информации определенного вида, например пресс-портрета или цитат.
Java IR Utils
2006-11-29 12:15 krondix
Я создал на Google Code проект Java IR Utils, куда буду выкладывать всякие полезности вроде SparseArrayList.
Анонимный доступ:
svn checkout http://java-ir-utils.googlecode.com/svn/trunk/ java-ir-utils
Контроль над поисковой выдачей
2006-11-28 10:40 krondix
Стоит отметить, что Yahoo запустил подобную поиск больше года назад и он как раз целиком направлен на исключение (или включение) магазинов из результатов.
Дальнейшим развитием этой идей должны быть уточняющие вопросы, то есть при запросе "слон" у пользователя должны спросить "вы хотите купить слона, посмотреть на слона или узнать про слона?" и, в зависимости от ответа, отсортировать результаты.
SparseArrayList, новая версия
2006-11-26 14:27 krondix
Заодно провел несколько измерений расхода памяти и скорости доступа по сравнению с HashMap и TreeMap.
- SparseArrayList позволяет сэкономить около 5% памяти по сравнению с HashMap
- Скорость произвольного доступа к элементам выше у HashMap при маленьком числе элементов (100-200) и становится одинаковой при большом числе (>5000)
- Скорость последовательного (по возрастанию индекса) доступа у SparseArrayList выше чем у TreeMap более чем в 2 раза
Как хранить double
2006-11-26 14:19 krondix
double[] (массив из одного элемента) и Double. Результат для меня был неожиданный: double/Double/double[] = 1/2/3. Получается, что в контейнерах эффективнее хранить класс-обертку, а не массив. Если же можно использовать массивы вместо контейнеров, лучше использовать массивы: выигрыш в памяти составит более 100%!
SparseArrayList
2006-11-24 15:27 krondix
В архиве лежит еще и класс Arrays (дополнение к стандартному) из MTJ. В библиотеке он package-local, для реализации SparseArrayList пришлось сделать его public.
Multiword Features
2006-11-20 20:51 krondix
В общем случае, шинглы — это уникальные последовательности символов одинаковой длины выделенные из документа. Для задач классификации можно рассматривать последовательности не символов, а слов. Например, для документа "a rose is a rose is a rose" шинглами длиной в четыре слова будут: { (a,rose,is,a), (rose,is,a,rose), (is,a,rose,is) }. Построить все шинглы для документа можно за
O(w(n-w)), где w — длина шингла. Дальше шинглы используются как обычные слова в классификаторе Байеса, за счет чего заметно вырастает точность, особенно когда мы работаем с иерархической структурой категорий.К сожалению шинглы нам не помогут в случае, когда слова из характерных сочетаний идут в документах не подряд, а на различном расстоянии друг от друга. В таком случае можно использовать обобщение идеи шинглов: multiword features. Собственно, что это такое уже понятно, весь вопрос в том, как эффективно эффективно найти характерные для категории multiword features. Действительно, наивный алгоритм, который находит все возможные сочетания слов, скорее всего просто не влезет в память. Очевидно, что нам нужны не все возможные сочетания слов, а только наиболее характерные для категории, то есть которые встречаются, например, как минимум в 10% документов. Это позволяет нам последовательно вычислять корреляцию для очередного набора слов и хранить в памяти только удовлетворяющие условию. Тем не менее, временная сложность такого алгоритма все равно будет
O(mk), где m — число слов в категории, k — число слов в наборе. Очевидно, что вычислять наборы более чем из двух слов неэффективно, да и, как правило, это не даст большого выигрыша в точности.Таким образом, нам осталось решить задачу вычисления корреляции между двумя словами в наборе документов, то есть число документов, в которых эти слова встречаются одновременно. Опять же, самый простой способ, когда мы проходим все документы и считаем вхождения слов в них будет достаточно медленным. Можно использовать следующий алгоритм вычисления корреляции:
- Каждое слово представляется вектором, элементы которого равны нулю или единице, в зависимости от присутствия слова в документе с соответствующим номером.
- Этот вектор хранится в виде
long[], длина массива равна[n / sizeof(long)] + 1, гдеn— число документов. - Вычисление корреляции между двумя документами сводится к последовательному побитовому умножению элементов двух массивов и вычислению числа единиц в результате.
Eigenvalue Decomposition
2006-11-06 22:41 krondix
Достаточно часто в задачах IR требуется найти собственные вектора какой-либо матрицы
nxn (eigenvalue decomposition, EVD), причем обычно нам нужны только k << n векторов соответствующих k наибольшим собственным числам матрицы. Но существующие в MTJ классы для вычисления EVD находят сразу все вектора, что приводит к совершенно неоправданным временным затратам. Для решения этой задачи я немного модифицировал класс SymmDenseEVD, который находит собственные вектора у симметричной матрицы. Теперь в конструкторе можно задать какие собственные числа (по убыванию) и соответствующие им вектора нам нужны.Binaries: mtj.jar
Source code: mtj-src.tar.gz
Не делайте лишнего
2006-10-31 13:01 krondix
||a - c||. Очевидный способ это сделать, используя библиотеку MTJnew SparseVector(vector).add(-1, centroid).norm(Vector.Norm.Two)add() приходится около 90% всех вычислений, возникает естественное желание попытаться его ускорить. Как работает этот метод? Для этого нам надо понять, как вообще устроен SparseVector.Для хранения разреженного вектора заводится два массива: массив индексов и массив значений.
Индексы отсортированы по возрастанию. При чтении элемента вектора бинарным поиском ищется его индекс, потом выбирается соответствующий индексу элемент из массива значений. Запись элемента происходит следующим образом: если по этому индексу уже есть элемент, то он просто перезаписывается, если же элемента нет, то оба массива раздвигаются в нужном месте (при необходимости увеличивается их длина) и сохраняется новый индекс и значение для него.
index
12
15
86
87
90
125
234
235
value
1.42
1.2
0.01
0.43
1.23
2.41
2.55
0.143
Как можно складывать такие вектора? Самый очевидный способ (который и реализован в классе
SparseVector) выглядит так:public void add(int index, double value) {
check(index);
int i = getIndex(index);
data[i] += value;
}
В getIndex() ищется место индекса в массиве и, при необходимости, создается место под новый. Его алгоритмическая сложность
O(log(n)), где n длина вектора, к которому мы добавляем. При этом нельзя забывать о достаточно большой константе связанной с раздвижением массива. Соответственно, общая сложность получается O(m log(n)), где m длина вектора, который мы добавляем.Конечно же, сразу хочется реализовать сложение векторов с помощью слияния двух массивов за
O(m + n). Вот только для некоторых m и n такое слияние будет даже медленнее чем первый способ. Например, для n = 100 и m = 20 (самые обычные значения во многих задачах).Как же нам улучшить производительность вычисления нормы разности векторов? Ответ прост, нам же совершенно не нужно вычислять разность векторов, это лишняя операция. Надо лишь на каждом шаге алгоритма слияния массивов вычислять очередное слагаемое нормы. Так мы избавляемся от затратной операции записи в массив и лишней операции чтения. После такой оптимизации скорость работы выросла в 3-4 раза.
Реализация алгоритма k-средних
2006-10-22 16:51 krondix
Документы-вектора можно представить несколькими способами, выбрав разные значения в качестве их элементов:
- 0 или 1, в зависимости от наличия слова в документе
- Число слов в документе
- TF*IDF данного слова
Полученную сильно разреженную матрицу надо не только хранить в памяти, но и иметь возможность эффективно выполнять разные операции над ними. Библиотек для работы со sparse matrices на Java не так много, а самое плохое, что я не нашел никаких benchmarks. Достаточно удобной в использовании мне показалась Matrix Toolkits for Java.
Радикально ускорить алгоритм можно с помощью уменьшения словаря, убрав из него слова мало влияющие на результат. Как правило, достаточно всего 20-30% слов, чтобы алгоритм работал с практически такой же точностью. Один из самых простых cпособов уменьшения словаря состоит в том, чтобы выбирать слова с наибольшей функцией качества:
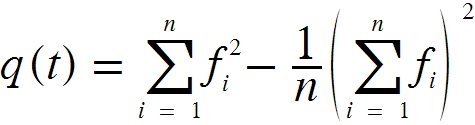
n — число всех документовfi — частота встречаемости слова в i-ом документе.Существует некий порог размера словаря, начиная с которого алгоритм k-средних начинает работать очень плохо. Обычно он лежит как раз в диапазоне 20-30%. Нужный размер проще всего подобрать экспериментальным путем.
Метод k-средних для обучения классификаторов Байеса
2006-10-21 22:50 krondix
 Здесь,
Здесь, Si — k кластеров, μi — центроид i-го кластера. На каждой итерации алгоритма мы перемещаем каждый вектор в кластер с ближайшим центроидом. Хотя не существует каких-либо оценок сложности алгоритма, на практике хватает он сходится за достаточно малое число итераций.У метода k-средних есть два серьезных недостатка:
- Необходимо заранее знать точное число кластеров.
- Качество результата сильно зависит от выбора начального разбиения.
Что будет если применить метод k-средних к задаче обучения классификаторов Байеса на некачественных данных? Действительно, ведь у нас уже есть готовы набор категорий-кластеров и начальное разбиение по ним. Я провел простой эксперимент. Тестовый набор включал в себя три категории документов, условно их можно назвать "Information Retrieval" (С1), "Java" (C2) и "HTML" (C3). Сами документы представляют собой короткие (несколько предложений) отрывки из статей в Википедии. Обучающую выборку я составил следующим образом: к каждой категории были отнесены 100 документов из нее самой и по 15 документов из двух других. После чего я применил Байеса ко всем 390 документам: 62 из них были классифицированны неправильно. Алгоритм k-средних разложил документы в обучающей выборке следующим образом:
C1 = 129 * C1 + 2 * C2Заново обученный Байес ошибся уже всего в 5 случаях!
C2 = 1 * C1 + 127 * C2 + 4 * C3
C3 = 1 * C2 + 126 * C3
Байес для сужения области поиска
2006-10-21 15:20 krondix
k результатов с наибольшей вероятностью, среди которых уже ищем окончательный ответ.Если копнуть чуть глубже, с помощью такого метода можно превратить линейную зависимость скорости работы самого Байеса от числа категорий в логарифмическую. Для этого надо построить классификатор похожий на decision tree, в котором решение в узлах будет приниматься с помощью Байеса. Формула для расчета вероятностей в таком классификаторе остается точно такой же, мы просто подставляем туда другие данные. Если объект принадлежит какой-либо категории, то он принадлежит и всем ее родителям, соответственно, слово описывающее объект также принадлежит всем родителям категории. При этом вероятность для каждого слова в категории надо считать относительно "братьев" этой категории, а не всех категорий сразу.
Есть еще один момент отличающий полученный классификатор от decision tree. Из каждого узла мы спускаемся вниз не по одному направлению, а сразу по нескольким, наиболее вероятным. Это нужно, чтобы не потерять маленькие категории внутри больших.
Результатом работы этого классификатора будет набор категорий, которые были им пройдены в спуске по дереву. Дальше мы применяем классического Байеса к этому набору и получаем искомый ответ за гораздо меньшее время.
РОМИП'2006
2006-10-16 12:30 krondix
19-го октября в Суздале пройдет четвертый РОМИП. Тем временем, на сайте семинара уже доступны труды участников. Приятного чтения!
