
Для ряда поисковых запросов наличие страниц в поисковой выдаче не требуется.
Yandex раскрыл алгоритм формирования фактовых ответов, а еще проговорился про формирование description.
Как поисковая система формирует быстрые ответы?
Рассмотрим тему далее.
1 — Колдунщики Яндекса. Что это?
Что такое колдунщики Яндекса? Колдунщики — это элементы поисковой выдачи, которые отвечают на поисковый запрос прямо на странице с результатами поиска. Это может быть прогноз погоды, картинка, перевод слова и многое другое. В результате пользователь проводит быстрый поиск и в большинстве из случаем не посещает сайты.
Пример колдунщика в поисковой выдаче: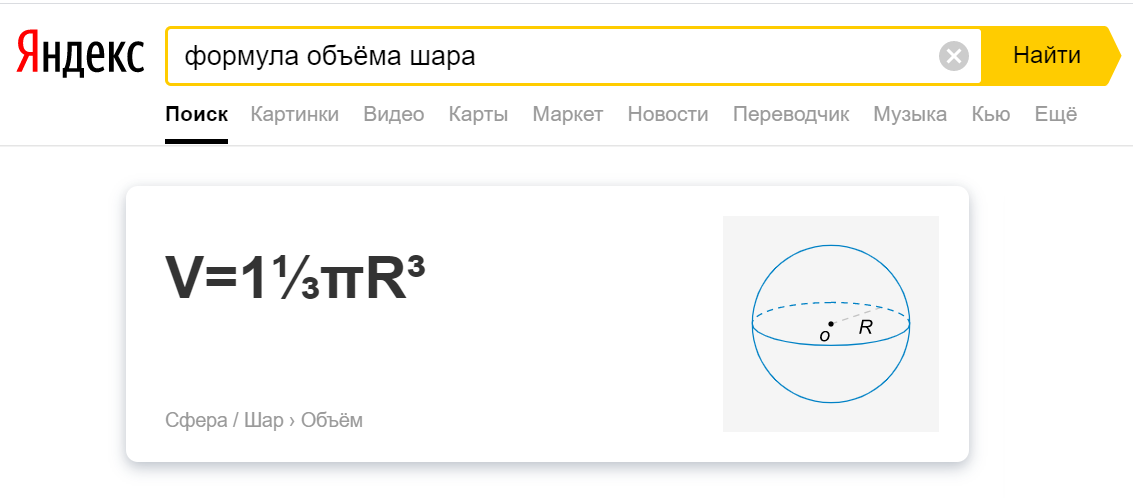
В поисковой выдаче Google есть блоки с подобными ответами.
Еще поисковые системы совершенствуются, переходят от поиска по ключевым фразам к поиску по смыслам (алгоритм BERT).
В результате поисковые системы монополизируют трафик. Рекомендованный материал в блоге MegaIndex на тему монополизации трафика по ссылке далее — Аналитические данные о поисковой выдаче Google, которые могут изменить планы на продвижение.
На языке инженеров такие блоки называются блоками с фактовыми ответами.
Как такие блоки формируются, чем различаются и что важного произошло в этой области за последнее время?
2 — Алгоритм Fact Snippet. Как формируются фактовые ответы
Сначала были имплементированы блоки без интерактивных функций, то есть блоки без взаимодействий. Например: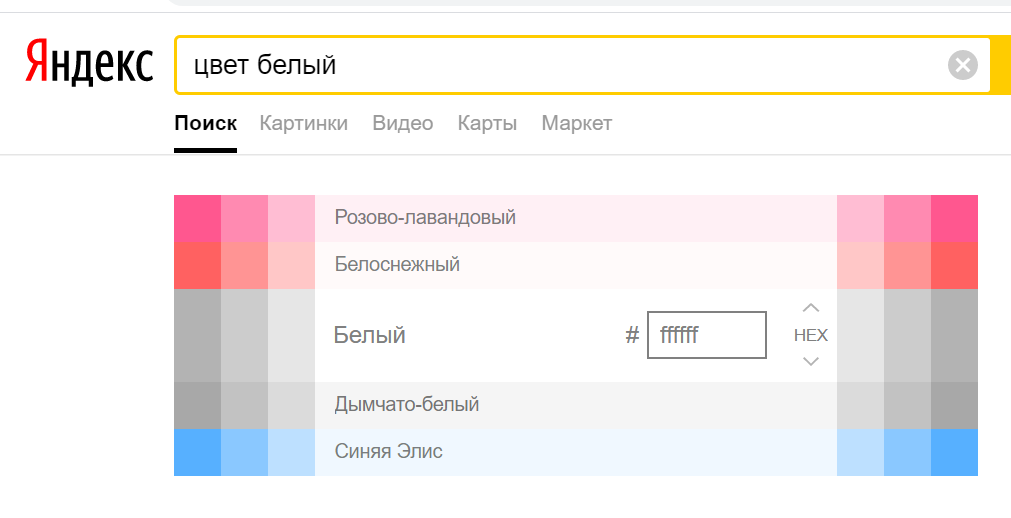
Ответы на подобные запросы встречаются в поисковой выдаче с высокой частотой. В результате многие сайты потеряли трафик. Например, поисковый запрос:
мой ip адрес
Раньше трафик забирал 2ip. Теперь трафик забрал Yandex.
Рассмотрим детали. Весь процесс создания таких блоков в поисковой системе выглядел так:
- Специальные сотрудники анализировали наиболее популярные запросы, выбирали те, на которые можно найти короткий ответ. Так были охвачены наиболее популярные ключевые фразы;
- Затем были использованы толокеры. Сначала выдвигалась гипотеза. Затем отвечали толокеры. Адекватность ответов перепроверялась.
Затем система получила еще ряд улучшений.
Был разработан алгоритм Fact Snippet. Сначала алгоритм должен был использовать текст из description. Имеется ввиду текст, который генерируется алгоритмом поисковой системы вне зависимости от фактического description. Но информативное описание страницы не во всех случаях является прямым ответом на вопрос.
Поэтому в Яндекс сделали так. Сначала нейросетевая модель была обучена на уже известных ответах. Затем происходит так — нейросетевая модель строит векторы ответов для найденных в поиске страниц и сравнивает их с вектором запроса.
Большинству запросов не требуется фактовый ответ. Поэтому в Yandex улучшили алгоритм для отсева нефактовых запросов. Задача была решена.
Дальше в Yandex поставили задачу по выходу за пределы фактов. Появился алгоритм Fact Snippet 2.
Пример ответа в поисковой выдаче: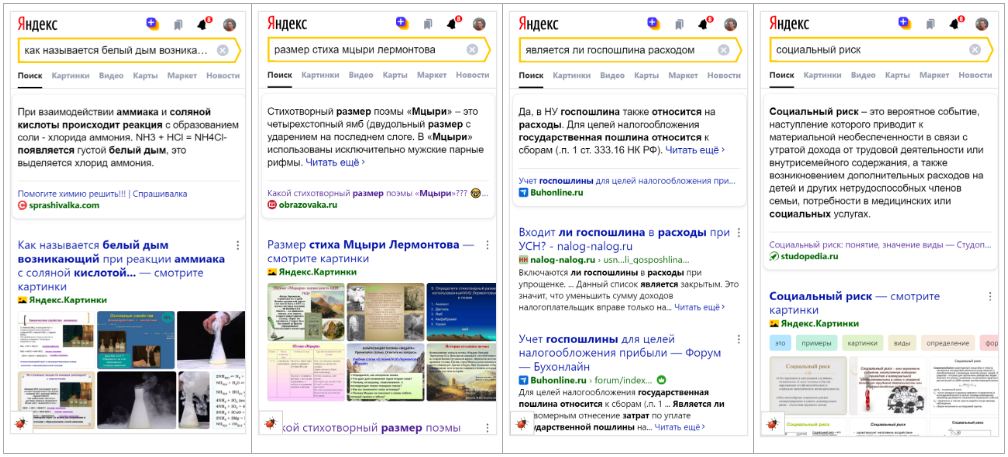
Если упростить, то Fact Snippet 2.0 — это тот же Fact Snippet, но без требования найти исчерпывающий ответ.
В Fact Snippet 2.0 адаптированы оба этапа так, чтобы находить ответы на более широкий срез вопросов.
Такие ответы не претендуют на энциклопедическую полноту, но всё равно полезны. Иногда хорошие ответы есть в иных источниках. Например, на картах. К примеру, зачем предлагать адрес организации текстом, если можно показать интерактивную карту, номер телефона и отзывы. Проблему решает блендерный классификатор.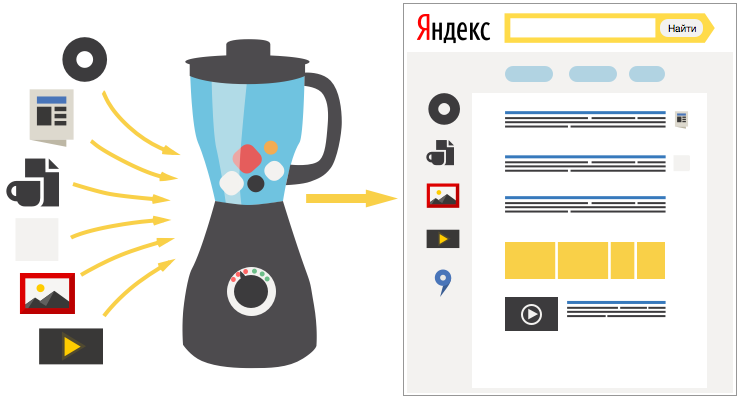
В результате еще больше ключевых фраз охвачены. В поисковой выдаче еще больше быстрых ответов. Но нет предела желанию монополизировать трафик. Алгоритм еще улучшили.
Переформулировки запросов. Часть поисковых запросов остались не охвачены. Существенная доля — таких ключевых фраз является переформулировками уже известных фраз. Например:
в какое время зубы меняет щука
и
когда щука меняет зубы
Данную задачу решает механизм поиска алиасов. Работает так:
- Берутся все запросы, на которые есть ответы;
- Преобразуются в векторы и кладутся в индекс k-NN. Применяется оптимизированная версия индекса HNSW, которая позволяет искать быстрее;
- Строятся векторы запросов, на которые нет ответа по прямому совпадению;
- Ищется топ N наиболее похожих запросов в k-NN;
- Далее топ прогоняется через катбустовый классификатор тройки: запрос пользователя, запрос из k-NN, ответ на запрос из k-NN;
- Если вердикт классификатора положительный — запрос считается алиасом запроса из k-NN, поисковая система может вернуть уже известный ответ.
Главная задача заключается в написании факторов классификатора. Самые сильные:
- Векторы запросов;
- Расстояния Левенштейна;
- Пословные эмбеддинги;
- Факторы на основе разнообразных колдунщиков по каждому из запросов;
- Расстояние между словами запросов.
Кстати определить смысловую близость запросов можно и другими способами. Например, если два запроса отличаются друг от друга одним словом, то как вариант можно проверить, как отличаются результаты поиска по этим запросам (посмотреть на число совпадающих ссылок в топе).
В быстром режиме искать алиасы не просто из-за ограничений по техническим ресурсам, потому применяют BERT. Сделали так:
- Собрали BERT-моделью очень много (сотни миллионов) искусственных оценок;
- Обучили на них более простую нейронную сеть DSSM, которая очень быстро работает в рантайме.
В результате с некоторой потерей точности удалось получить сильный фактор.
3 — Нейросуммаризация поиска. Сайты больше будут не нужны
Далее в поисковой системе Yandex стоит задача по созданию ответов на базе разных источников. Речь про проект нейросуммаризации поиска. Иными словами, сайты будут источником контента, а поисковая система будет генерировать ответ на базе найденного контента на сайте.
Интересный нюанс
В ходе разбора работы алгоритма фактовых ответов Яндекс рассказал про формирование текста для сниппетов страниц. Поисковая система способна автоматически создавать текст для сниппета.
Как создается текст? Алгоритм ищет лучший фрагмент текста на странице. Применяется модель CatBoost, которая оценивает близость фрагмента текста и запроса.
По сути алгоритм нацелен на то, чтобы выдать в тексте сниппета фактический ответ.
Здесь открывается поле для манипуляций. Значение для сниппета задается через description. Например, для сайта indexoid:
Но прописывать значение для description является необязательным условием для индексации страницы.
В результате поисковой есть вариант:
- Создать группы страниц без описания. Например, копии страниц лидеров поиска;
- Выявить какой именно фрагмент текста является лучшим ответом на ключевую фразу;
- Применить полученные данные в текстовой оптимизации страниц сайта.
Еще пример:
- Создать группы страниц без описания. Например, группы страниц на одну тему, но с разным текстом;
- Выявить какой именно фрагмент текста является лучшим ответом на ключевую фразу;
- Применить полученные данные в текстовой оптимизации страниц сайта.
По сути, поисковый алгоритм сравнивает два вектора: вектор запроса и вектор текста документа.
Чем ближе векторы в многомерном пространстве, тем ближе смыслы текстов по данным поисковой системы.
Выводы
В поисковой системе Yandex переходят от поиска страниц по ключевым фразам к поиску ответов. В результате будет реклама поисковой системы и прямые ответы, а трафик на страницы сайтов будет идти лишь через навигационные ключевые фразы.
В поисковой системе Google двигаются аналогичным образом. Рекомендованный материал в блоге MegaIndex на тему поиска по смыслу по ссылке далее — ГУГЛ БЕРТ.
Fact Snippet работает в два этапа. В Fact Snippet 2 принцип подобный, но есть нюансы. Этапы в Fact Snippet следующие:
- На первом этапе с помощью лёгкой модели оценивается фактовость запроса, иными словами проверяется фактовый ответ или нет;
- Если да, ответ выводится в поисковой выдаче.
Для Fact Snippet 2.0 адаптированы оба этапа так, чтобы искать решение по более широкому срезу вопросов. Такие ответы не претендуют на энциклопедическую полноту, но всё равно полезны.
Сниппеты сайтов влияют на кликовые факторы.
Для увеличения кликабельности в поисковой выдаче следует создавать привлекательный текст, и для решения задачи по созданию кликабельных сниппетов можно использовать анализ сниппетов страниц конкурентных сайтов.
Ссылка на сервис — Анализ сниппетов.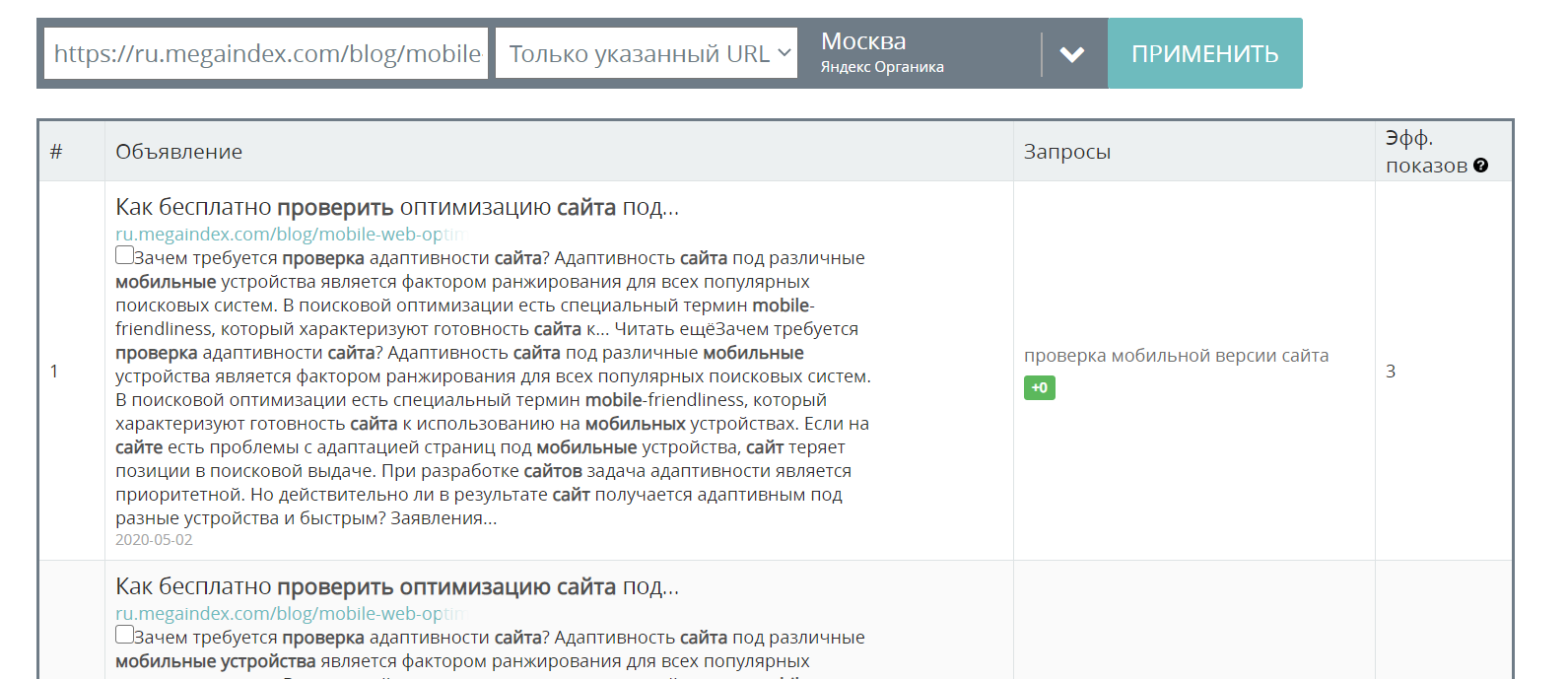
|
Это интересно
0
|
|||


Последние откомментированные темы:
-
Изменение ссылок
(1)
casham
,
01.02.2012
-
Плагин Special Text Boxes
(2)
Ирина
,
27.12.2011
-
Как закрыть ссылки от индексации быстро и красиво. Плагины WP-NoRef и WP No External Links.
(2)
-
Вышел WordPress 3.3 русская версия
(1)
casham
,
16.12.2011
-
Что нового в WordPress 3.3
(1)
casham
,
16.12.2011
-
10 сервисов для создания интересных продуктов на основе ваших фото из Instagram
(1)
Mike Kovalev
,
14.12.2011
20240419232027megr***@m*****.ru , 18.12.2011