Рассылка закрыта
При закрытии подписчики были переданы в рассылку "Левитас: Почему Ваш бизнес-сайт не работает?" на которую и рекомендуем вам подписаться.
Вы можете найти рассылки сходной тематики в Каталоге рассылок.
Профессиональное продвижение сайтов. Пособие от SeoPult
|
 Новый докладчик от «Яндекса» на конференции CyberMarketing-2011!
7 октября в Москве на конференции CyberMarketing-2011 от «Яндекса» выступит Кирилл Николаев, руководитель группы в отделе веб-поиска. Поскольку мероприятие имеет практическую направленность, мы пригласили не человека из менеджмента, а специалиста, работающего над поиском «Яндекса».
Новый докладчик от «Яндекса» на конференции CyberMarketing-2011!
7 октября в Москве на конференции CyberMarketing-2011 от «Яндекса» выступит Кирилл Николаев, руководитель группы в отделе веб-поиска. Поскольку мероприятие имеет практическую направленность, мы пригласили не человека из менеджмента, а специалиста, работающего над поиском «Яндекса».
 Бесплатный обучающий курс по заработку в сети – составь программу на свой выбор!
Посещайте семинары Центра CyberMarketing в комплексе: вы можете организовать себе целый обучающий курс по заработку в сети, и к тому же – совершенно бесплатный!
Бесплатный обучающий курс по заработку в сети – составь программу на свой выбор!
Посещайте семинары Центра CyberMarketing в комплексе: вы можете организовать себе целый обучающий курс по заработку в сети, и к тому же – совершенно бесплатный!
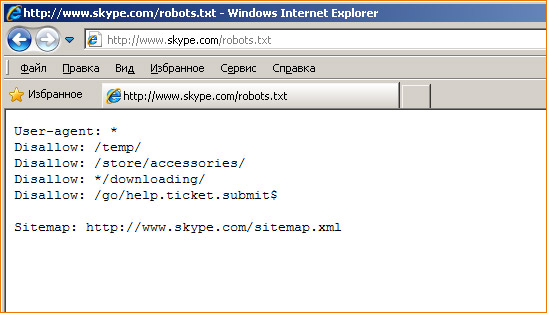
 Настройка robots.txt
Настройка robots.txt

 Новые рекламные возможности «Яндекса»
Новые рекламные возможности «Яндекса»
 Вопрос: Я много времени потратил на оптимизацию сайта и внутреннюю перелинковку, но результаты от продвижения меня не устраивают. Думаю о том, чтобы начать закупать ссылки, но не знаю, как покупать хорошие и думаю, что нецелесообразно покупать слишком дорогие ссылки – можно ли как-то настроить закупку ссылок в SeoPult по их стоимости?
Вопрос: Я много времени потратил на оптимизацию сайта и внутреннюю перелинковку, но результаты от продвижения меня не устраивают. Думаю о том, чтобы начать закупать ссылки, но не знаю, как покупать хорошие и думаю, что нецелесообразно покупать слишком дорогие ссылки – можно ли как-то настроить закупку ссылок в SeoPult по их стоимости?
| В избранное | ||
